Session 8
Inductive Definitions of Data
Opening Exercise—Not
Our next unit is called
Inductive Specifications & Recursive Programs
.
While noodling around to get ready for this session a few years back, I ran across a short video with an interesting puzzle. Can you solve it?
[a|b|c],
each 1-2-3.
We can only move a and b together, or b and c.
What sequence of moves gets us from [3|3|3]
to [2|2|1] ?
It's a trap. You can't. And then someone sneaks in an inductive proof to show why.
Problems like this can be a lot of fun, and they make fine mathematical examples of inductive reasoning. But they feel like tricks: puzzles meant to challenge us for the sake of the challenge. Some people like such puzzles (I am one!), but they may not be the best way for a computer scientist to learn induction or recursion.
We computer scientists work with structures that make induction more tangible to us.
Opening Exercise
(w h a c k)How about this?
(m o l . e)
We can answer these questions at a glance, because we can take
in the entire list in one view. All we need remember is the
jingle A list is a pair whose cdr is a list.
But our
computer programs cannot do this.
When a Racket function receives such an object, it receives a cons cell:
[e ...]
It can take the car and see e. It can take the
cdr and see... a pointer to another object.
When it looks at that pointer, it sees another cons cell. In
the car it sees a b, but that doesn't affect
whether the structure is a list or not. In the cdr it sees
another pointer...
It keeps doing this, until eventually the cdr is either one final object, or a null pointer.
e [ .......... ]
b [ ...... ]
a [ .. ]
r []
In this case, we find null pointer — an empty list — and know we have seen a list.
If at the end the last cons cell is (a . r), we
know that we don't start with a proper list. We received
(e b a . r).
We use data structures like lists and trees all the time. If we we have better tools for describing them, we will have better tools for reasoning about them.
Data Types and Values
Recall that a data type consists of two things: +
As programmers, we are also concerned with other pragmatic issues, such as how values are represented as literals in programs and how values are represented for reading and printing. But these are interface issues that are essentially external to the data type itself.
- a set of values, and
- a set of operations on those values.
In order to define operations on the values of a data type, we need a way to specify the set of values in the type. That way, we can be sure to handle all possible values of an object. More generally, we want to be able to recognize whether or not a value is in the set in order for our language processors to do type-checking.
Inductive Specification
Suppose that I wanted to describe the set lists of symbols, like the ones we considered earlier. I might write:
()is in the set.-
If
s1is a symbol, then(s1)is in the set. -
If
s1ands2are symbols, then(s1 s2)is in the set. - And so on.
We all understand this definition because we intuitively recognize the pattern. This specification relies on the reader to determine the pattern, add one more symbol to the previous list, and to continue it.
But what if the "reader" is a computer program? Programs aren't nearly as strong at recognizing conceptual patterns in infinite lists. +
... "—yet", says the old AI guy. Researchers are making more powerful LLMs every day.
This type of specification can even cause problems to a human
reader. Does "and so on" used above mean what we think it
means? I think it means, for example, that if s1,
s2, and s3 are symbols, then
(s1 s2 s3) is in the set. But can I be sure?
So we can only use such specifications safely with human readers if we have a shared understanding of how to identify the pattern. When multiple reasonable patterns exist, we must have a common sense of simplicity. +
This is one of the things that always bothered me about analogy problems on exams like the ACT and SAT. How could I know if I was using the simplest rule if no one had ever taught me the rules?
Rather than list examples and rely on the reader to determine the pattern, we can usually write a more concise and more explicit definition of a set by defining the pattern in terms of other members of the set. For lists of symbols, I might write:
()is in the set.-
If
sis a symbol andLis in the set, then(cons s L)is in the set.
Now we know that (a b c) is in the set:
-
()is in the set. (Rule 1) -
Therefore,
(c)is in the set. (Rule 2) -
Therefore,
(b c)is in the set. (Rule 2) -
Therefore,
(a b c)is in the set. (Rule 2)
Using this definition, we can generate all list of symbols of length 0 or more. The only thing we depend upon is the cons operation.
This way to define a set is called inductive.
Inductive definitions are a powerful form of shorthand. Though many of you cringe at the idea of an inductive proof, most of you think about certain problems in this way with ease. (Writing a proof requires a few proof-making skills, along with more precision — and thus more discipline.)
The second part of our definition above is the inductive part. It defines one member of the set in terms of another member of the set.
We can use this style to define other kinds of sets, too. For example, if I want to describe the sequence 1, 2, 4, ..., I can write:
- The number 1 is in the set.
- If n is in the set, then 2n is in the set.
Reasoning inductively is something humans do pretty well automatically, and it turns out to be a useful technique to embody definitions in computer programs, too. We relied on an inductive definition in Session 4 when we said A list is a pair whose second item is a list.
We can even use an inductive definition to specify what counts as an arithmetic expression:
- Every number is an arithmetic expression.
-
If
mis an arithmetic expression, then-mis, too. -
If
mandnare arithmetic expressions, then(m + n)is, too.
This can be handy for type checking computer programs... and much more. We return to this idea soon!
Backus Naur Form (BNF)
Inductive specifications are so plentiful and so useful that computer scientists have developed a specialized notation — a language — for writing them.
In case you haven't noticed,
most of computer science is about notation
— and thus about language —
in one form or another.
The notation we use to write inductive definitions is called Backus-Naur Form, or BNF for short. + You will see BNF used in a number of places, including most programming language references, and computer scientists will expect that you know what BNF is.
Footnote: Who Are Backus and Naur?
I sometimes introduce John Backus in
Session 1,
because he was the leader of the first compiler project in
history. For this and his many other contributions to computing,
Backus received
the Turing Award
in 1977.
Peter Naur also received the Turing Award, in 2005. Naur's award
recognized fundamental contributions to programming language
design and the definition of Algol 60, to compiler design, and to
the art and practice of computer programming
.
The first Turing Award was given in 1966 to Alan Perlis —
another name we've seen this semester, in
this quote on languages
changing how we think. By now, I hope that you are not surprised
that so many of the giants of computing made their biggest
contributions to the discipline in the area of programming
languages. As stated above,
most of computer science is about notation — and thus about
language — in one form or another.
BNF notation has three major components:
- a set of terminals that require no further definition,
- a set of non-terminals that are defined in terms of terminals and other non-terminals, and
- a set of rules that, for each non-terminal, precisely state how one can construct the non-terminal in terms of terminals and other non-terminals
You will sometimes see terminals ignored altogether, because they are obvious to the reader. Suppose that I wished to define a "list of numbers". I may assume that my readers will know what I mean by a "number" and so not define it with a rule. If that turns out to be a problem (for example, do negative numbers count? floating-point?), I can always add a rule or two to define numbers.
Here is the BNF definition for a list of numbers in Racket:
<list-of-numbers> ::= () <list-of-numbers> ::= (<number> . <list-of-numbers>)
This definition is inductive, because the second rule defines one list of numbers in terms of another (shorter!) list of numbers. It matches the catchy definition I gave for a Racket list back in Session 4: a list is a pair whose cdr is a list.
There are a few things to notice about the BNF definition:
-
::=is the symbol denoting a definition and is read "...is defined as..." -
The dot and the left and right parens —
.,(, and)— are the terminals in this definition. -
<list-of-numbers>is a non-terminal. We often denote non-terminals by enclosing them in angle brackets.
What about <number>? Is it a terminal or
a non-terminal? It is written as a non-terminal. We might
assume that it stands in place of the numeric literals 0, 1,
2, and so on, and thus requires no formal definition. But we
really should define <number> formally, too:
<number> ::= 0 <number> ::= <number>+1
As you can see from these definitions, there may be more than one rule for a non-terminal. This happens so often that there is a special notation for it:
<list-of-numbers> ::= ()
| (<number> . <list-of-numbers>)
<number> ::= 0
| <number> + 1
We read the vertical bar, |, as
"... or ...".
As a shorthand, we will sometimes use another piece of notation,
called the Kleene star, denoted by
*. The star says that the preceding
element is repeated zero or more times. Using the
Kleene star, we can define a list of numbers simply as:
<list-of-numbers> ::= ( <number>* )
Another variation is the Kleene plus, denoted by
+. This notation differs from the
Kleene star in that the structure within the brackets must
appear one or more times.
In this course, we usually write our definitions of data types using the more verbose notation given in the first definition above. The more verbose notation provides us with guidance as we think about the code that processes our data, which will help us write our programs.
Syntactic Derivation
We can use our inductive definitions, whether in BNF or not,
to demonstrate that a given element is or is not a member of
a particular data type. This is just what we did above when I
deduced that
(a b c) is a list of symbols
and when I asked how might we convince someone that
32 is a power of 2.
For another example, consider (3540 4550). We
can use the technique of syntactic derivation to show
that it is a member of the data type
<list-of-numbers>:
<list-of-numbers> (<number> . <list-of-numbers>) (3540 . <list-of-numbers>) (3540 . (<number> . <list-of-numbers>)) (3540 . (4550 . <list-of-numbers>)) (3540 . (4550 . ()))
Recall that (3540 4550) and
(3540 . (4550 . ())) are two ways of writing the
same Racket value!
You shouldn't be surprised that syntactic derivation resembles Racket's substitution model. They are closely related. As in the substitution model, the order in which we derive the sub-expressions is not important.
Using BNF to Specify Other Data Types
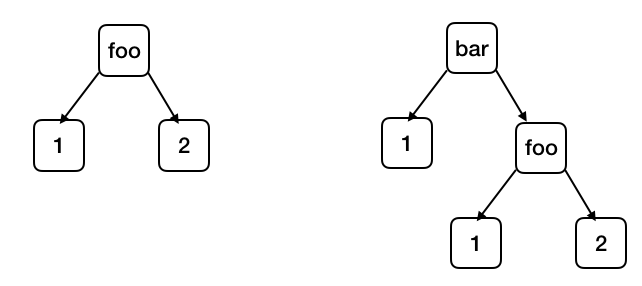
We have just seen how we can specify a list of numbers using BNF. We can use BNF to specify other data types as well. For example, we can specify a binary tree that has numbers as leaf nodes and symbols as internal nodes as:
<tree> ::= <number>
| (<symbol> <tree> <tree>)
This BNF specification describes trees that look like the following:
1 (foo 1 2) (bar (foo 1 2) (baz 3 4)) (bif 1 (foo (baz 3 4) 5))
We will see many more examples of BNF throughout the course. It goes hand in hand with inductive definitions. Earlier today, we defined a simple set of arithmetic expressions inductively. That definition specifies a set of numbers, but it also specifies the sort of expressions we write in computer programs. Is that resemblance accidental? No, it reveals something deeper.
Quick exercise: Give a BNF definition for the set of arithmetic expressions defined above.
An important use of BNF is in specifying the syntax of programming languages. It may seem odd that a method we just described as being useful for specifying data types would be useful for specifying syntax, but remember: a compiler is a program that treats other programs as data. In other words:
Syntax is just another data type.
This is a powerful idea. Let it sink in.
Syntax is only one way to think about a language.
The notion that syntax is a data type actually takes us a bit farther along our path of studying programming languages. How else might we understand a language? With some help from Shriram Krishnamurthi's book, Programming Languages: Application and Interpretation, I can think of at least four ways:
- its syntax (the rules that govern expressions in the language)
- its semantics (the behavior associated with each kind of syntax)
- its libraries of functions and classes
- the patterns used by programmers of the language
All four of these are important to programmers, especially those who want to use the language to build big systems. In a course on programming languages, our focus is on syntax and semantics, with an emphasis on the latter: How can a program implement the behaviors we desire? How can a programming language describe those behaviors? How can an interpreter or compiler process a program?
Though it might seem like it to yet, because you are still early in your study of computer science, but in many ways, syntax is the least important of these four features. Familiar or not, terse or not, it doesn't matter all that much, at least relative to the other features. You'll see.
BNF gives us a tool for describing syntax. Programs that process BNF descriptions recursively give us a tool for understanding behavior.
Moving Forward: Data Types and Values
A data type consists of two things: a set of values and a set of operations on those values.
This session shows how we can use BNF notation to define sets of values.
Next session, we will begin learning a family of techniques for writing operations — programs that process values in the sets — using the BNF definition as a guide.
Following an inductive definition will help us write complete programs, ones that handle all possible inputs. But doing so will also help us write correct programs, converting a big problem into three or more smaller problems that are easier to solve. On to Session 9!
Wrap Up
-
Reading
- Read these notes, paying attention to any ideas we did not discuss in class.
- Read this short introduction to iteration and recursion. It covers some vocabulary and reviews some ideas you have seen before. Reading it will prepare us to start writing programs over inductively-defined sets next session.
-
Homework
- Homework 4 will be available after the next session.
-
Quiz
- Quiz 1 is today.