More Thoughts on Building a Language Interpreter
Introduction
This reading discusses some ideas that come up often when we discuss how to implement a language interpreter.
Processing Programs
Terminology
You began to write your own language interpreter on Homework 9, for a simple language for creating and manipulating numbers. An interpreter takes a program as input and produces as output the behavior of the program. At this point, our language is purely functional, so a program's behavior is its value.
But you did more than write just an interpreter. You wrote several other functions. Let's consider the full scope of what you have done.
We are now able to talk about multiple languages ...
- the source language: Huey. This is the language that programmers use to write programs to solve their problems.
- the implementation language: Racket. This is the language we use to implement the language processor (the interpreter, the compiler, the IDE, etc.).
... and multiple kinds of program:
- a source program: a Huey program written to solve a problem.
- the program processor: your Huey evaluator, including the pre-processor. It processes a source program written in Huey.
We have not yet written a read-eval-print loop (REPL) for Huey yet, but when we do, it will use your other program processors to implement a more complete interpreter. The stages of a REPL include:
-
read a source program
- parse the program into some structure
- preprocess the structure to eliminate syntactic abstractions
- evaluate the program
- print its result
This is a pipeline of sorts. Pipelines are the way we do functional programming in a Unix shell.
Parse
This stage converts a program from its concrete syntax to an abstract syntax. In most languages, even Racket, the internal representation of a program is different from the surface syntax we see in Racket code.
We do not need to write a parser. We use parenthesized expressions and values that Racket knows about, so we can rely on Racket's reader to read and parse an expression into a Racket list. That simplifies our job considerably.
However, our syntax procedures simulates abstract syntax.
Our Huey-processing functions do not have to care about the
concrete of Huey, only the essential parts of the
expressions. There should be no firsts or
rests in your language processing code except
in the syntax procedures themselves.
Preprocess
This component takes an input program from the full language grammar and translates into a program that uses only the core features of the language. Writing a preprocessor allows programmers to use syntactic sugar without cluttering the rest of the interpreter with syntactic abstractions.
We implement the preprocessor using structural recursion. The task is to translate expressions from one grammar into expressions from a smaller grammar. We have to handle all sub-expressions, so the preprocessor is recursive. If one or more of the cases is long or complicated on its own, we can write a helper function to do the work.
Evaluate
We have several choices to make when writing the evaluator.
- the structure of the evaluator: a familiar friend. Follow the BNF!
- the decision whether to create types for numbers and other base types that are our implementing language already has
- the decision of how to implement the functionality of operators, under the same conditions
There are at least three ways to implement the behavior of Huey operators, with varying trade-offs.
-
embed the behavior directly into the
eval-expfunction - write a Racket function for each operator at the top level, and call these from the evaluator
- write a Racket function for each in a local namespace, and call these from the evaluator
We should try to balance the forces of our situation, with a bit of an eye on the future. How closely do Racket semantics match Huey semantics? Will we want to add new operators? Will we want to change the implementation of existing operators? For example, we may want to add local variables to the language, or static data types, or functions, or ....
We will be extending our language and its interpreter for the next two weeks. Show care in creating good code, not just code that scores homework points. You will be glad you did, both for future assignments and for the sense of accomplishment you will have when you have created a real program.
Next Steps
Homework 10 adds local variables to the language. To do this, we need an environment. Each new scope creates a new environment that extends (and shadows) the existing environment.
This requires a change to the evaluator: the interface
procedure must create an initial environment, and every call
to the evaluator requires that we pass the environment to be
used to evaluate the expression. (This may remind you of
lexical-address
and its initial variable table.)
On Homework 11, we will use the evaluator's environment to add mutable data to Huey, which will allow us also to add sequences of statements. Time permitting in class, we will show how how we can use the environment to add functions to the language. One idea can give us a lot of power.
Note. This is the end of the reading. What follows are two footnotes that were linked to above.
Footnote: Concrete Syntax
Throughout this course, we have been writing most of our programs in a particular style, which is sometimes called syntax-directed programming. This name comes from the idea that the BNF description of a data structure's syntax guides us in structuring our code. In syntax-directed programming, we associate a particular behavior with each part of a grammar.
This should sound familiar! It is the whole basis for the technique of structural recursion that we first learned about in Session 9. As you might guess, this style of programming is especially useful for implementing programs such as compilers and interpreters.
Up to now, we have focused our attention on
concrete syntax — that is, the program form
designed for the human programmers who use the language.
Concrete syntax worries about the correct placement of
semicolons and periods and parentheses, the exact format of
the if statement, and so on.
For example, in Session 12 we began to work with a
little language
to which we later added if and let
expressions. This little language has a concrete syntax based
on Racket's, down to the parentheses. My decision to use a
Racket-like concrete syntax was purely pragmatic: it allows us
to use Racket's primitive procedures for lists when processing
our expressions. You might have preferred a different concrete
syntax.
While the issues involved with the language's concrete syntax
are quite important to programmers when they write programs,
the concrete syntax can get in the way when we are trying to
understand the meaning of a program. For example,
consider the form of the if statements in a few
languages:
if <test> ;; Pascal
then <consequent> ;; statements are
else <alternate> ;; semicolon-separated
(if <test> ;; Racket
<consequent> ;; expression
<alternate>)
if (<test>) ;; Java/C/C++
<consequent> ;; statements are
else ;; semicolon-terminated
<alternate> ;;
<test> ifTrue: [<alternative1>] ;; Smalltalk
ifFalse: [<alternative2>] ;; expression
Even though these statements are written in different ways, they are all the same at a deeper level — at the semantic level, in terms of what they mean. When we devote all of our attention to the concrete form of expressions, we can easily lose sight of their content. This is true when we are writing a program in the language, and it is also true when we are trying to implement a language processor.
As in any programming endeavor, we would like for our language processors to exhibit a separation of concerns. The part of our code that must know about the form of expressions should be distinct from the part that knows about the meanings of expressions. That way, we can change the concrete syntax of a language — even add syntactic abstractions! — without having to modify the interpreter.
Further, with proper separation of concerns, we can also change the semantics of a language without changing the parts of our programs that process concrete syntax. While this is much less likely to happen (why?), it does happen. Consider the addition of auto-boxing to Java 1.5....
[ return to discussion of parsing ]
Footnote: Abstract Syntax
Abstract syntax expresses the content of an expression in a language, minus the syntactic details of the concrete syntax. To create an abstract syntax from a concrete syntax, we associate a name with each arm of the concrete syntax definition and with each of the non-terminals. Each arm is called a production rule, because it defines a rule for producing a legal expression.
As an example, consider the little language that we have
studied over the last few weeks. We might express the abstract
syntax for this version of our lambda-based
language as follows. The names to the right are the production
names and the values in parentheses are the names of the
non-terminals in the order of their appearance.
CONCRETE SYNTAX ABSTRACT SYNTAX
--------------- ---------------
<exp> ::= <number> literal-exp (datum)
| <varref> variable-exp (var)
| (lambda (<var>) <exp>) lambda-exp (formal body)
| (<exp> <exp>) app-exp (operator operand)
Notice that I have extended the grammar that we've used in the past to include numeric literals.
The most common method for representing the abstract syntax of
an expression is the abstract syntax tree (AST), also
sometimes called, inaccurately, a parse tree. (You
can learn the difference — and much more — if you
take the compiler course next semester.) The interior nodes
of an AST are labeled with production names, and the leaves
correspond to the terminals that make up the expression. For
example, the abstract syntax tree for
(lambda (f) (f (f 10))) is:
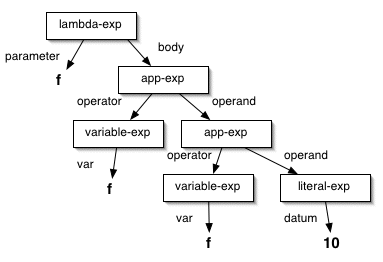
(lambda (f) (f (f 10)))
ASTs are n-ary trees, because some expressions have
more than two parts. For example, the expression
(if f x y) has three elements in its abstract
syntax: the variable expressions f,
x, and y.
[ return to discussion of parsing ]