Week 1: The Architecture of the Web
About the Weekly Readings
Every week of the course will have a page of readings about the topics for the week.
Question 1: Do I need to read the weekly readings?
Yes, you do need to read the weekly readings. They introduce ideas and tools that we use in the course. We will discuss these ideas and tools in class, but we will not usually cover in class everything that appears in the readings. Material in the readings will appear on the midterm exams.
Question 2: What about the many links in the page?
The weekly readings include many links to external resources, documentation, articles, blogs, and sample code. No one resource can begin to cover the breadth and depth of web development. The external links will help you understand and master the material. You don't have to follow every link, or to read deeply if you so. But I recommend that you study some of the external material, as time permits.
To get good at the web, you will want to be curious and to explore beyond where this course can take you. You need to experiment. If you have time, read some of the resources available in the notes to help you begin exploring.
Starting next week, most of the weekly readings will begin with a section labeled Recommended Readings. Those links will point you to documentation for the features of HTML, CSS, and JavaScript that we will be learning that week. Make sure that you do browse the links in that section, as they are the main topic of the week's learning.
The Internet: A Quick Introduction
The Internet is... a wire.
The Web: A Quick Summary
We often use the terms "Web" and "Internet" interchangeably, but they aren't the same. The World Wide Web (WWW) is a subset of the Internet. It runs on top of the Internet using the HTTP protocol. It allows us to access web services, request resources such as pages and images, and transmit data between clients and servers.
The web is the most ubiquitous computing platform in the world, running on all kinds of hardware, built out of hundreds of languages, libraries, and frameworks, some old, some new, all being mixed together at once.
The essential reality of the web is its interconnectedness. Its fundamental unit is the hyperlink.
Why Learn the Architecture of the Web?
Before we move into markup and client-side web programming, let's take a closer look at the underlying technologies: the Internet and the World Wide Web. This course is not just about learning to write HTML, CSS, JavaScript, or any other markup or programming language. We want you to gain an understanding of how this technology works. Such knowledge offers power and flexibility: you can do much more, and you are not limited to the examples you may find online. You will create your own.
It is not necessary to understand how the Web works (or how it came to be) if what you need is a specific visual effect for your web page. In that case, you simply find the right code snippet on the web, and maybe even read an explanation of how to use it on StackOverflow. You then copy the snippet into your web page, cross your fingers. and hope nothing breaks. Of course, when something does go wrong, you waste hours — or days — figuring out which part of the code you borrowed is causing the problem.
The goal of this course is to give you a deeper understanding of building web pages than what is required to be able to cut and paste bits of code. Knowledge of the core technological aspects of the Web and the Internet is essential for any kind of web development, which is why we introduce both the Internet and the World Wide Web at the beginning of our course.
The Internet: Historical Highlights
- 1957: USSR launches Sputnik 1
- 1958: US President Eisenhower creates the Advanced Research Projects Agency (now DARPA) in response.
-
1969: ARPANET
goes online:
- It is a decentralized, distributed network.
- The network uses "packet switching": each message is broken up into chunks and is then reassembled at its destination.
- 1973-74: Vint Cerf and Bob Kahn create TCP/IP, a set of protocols. A protocol is a set of rules everyone agrees to follow to communicate on a network. The term “Internet” is coined around this time, to describe how different networks can communicate with each other — that is, how they "internetwork".
- 1983: TCP/IP is adopted across ARPANET. We can consider the birth of the modern Internet.
The World Wide Web: Historical Highlights
The web was invented by Tim Berners-Lee, a British physicist-turned-computer scientist working at CERN.
- 1989: Berners-Lee first circulated a proposal for a new kind of an information management system.
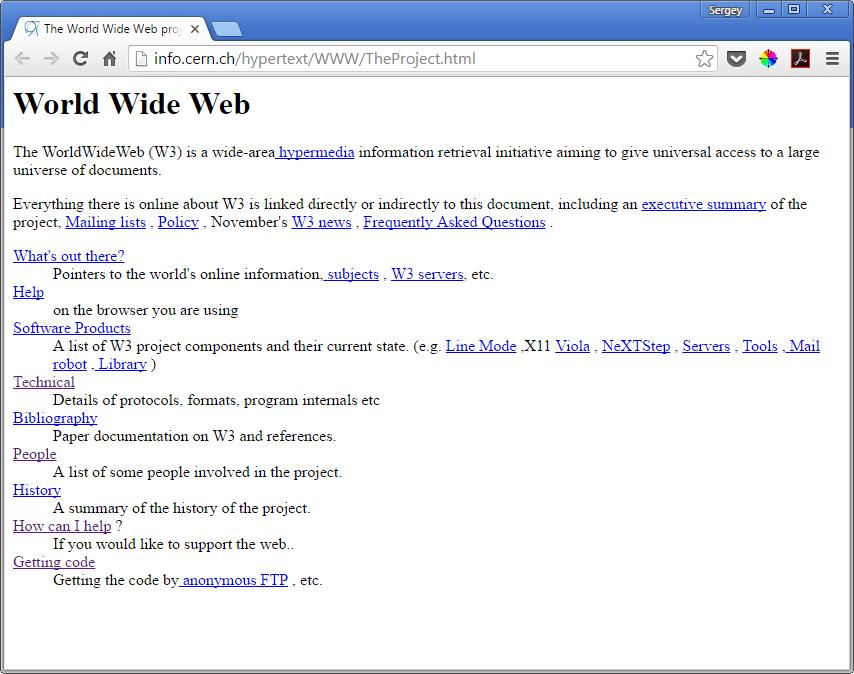
-
1990: The first web page
goes online.
-
1993: Scientists at the National Center for Supercomputing
Applications (NCSA), at the University of Illinois, create
Mosaic,
the first graphical web browser. Before then, browsers
for reading the web were text-based.
- 1994: The World Wide Web Consortium (W3C) is founded. The W3C is the international standards organization that oversees the growth of the web. Its recommendations are followed by the software manufacturers who produce the technology that enables the Web: the servers, the browsers, and so on.

Core Features of the Web
These are the essential concepts that make up the web:
- URL (uniform resource locator): a unique address to identify a resource on the Web
- HTTP (hypertext transfer protocol): a set of rules than enable a local computer, the client, such as your web browser, to communicate with a remote computer, the server.
- web server: a program residing on the server that is responsible for handling client requests. Note that the term "server" can refer to both the computer and the software that runs on it.
- web browser: a program residing on the client that is capable of making requests to the server based on the provided URL. It then displays the HTML it receives from the server. Note again that the term "client" can refer to both the computer and the software that runs on it.
- HTML (hypertext markup language): the markup language used to describe the content of a web page.
We have now seen the names of two protocols: TCP/IP (which is really a suite of protocols) and HTTP. There are many others: HTTPS, DNS, SMTP, IMAP, ... which are important to how the web works. They are beyond the scope of this course.
Neither CERN nor Berners-Lee patented this technology. The web isn't owned or controlled by any single organization, company, or government. Instead, it is defined as a set of open standards, which everyone building and using the web relies upon. Some examples of these standards include HTML, HTTP, and many more.
The growth of the World Wide Web over the past decades has been made possible by this decision.
The Client-Server Model of Communication
The Web is based on a client-server model of communciation:
- The client makes a request to the server for some resource — an html file, a media file, etc. — using its URL.
- The server processes the request and sends a response consisting of the requested resource and additional information about the response.
- The client processes the server's response and displays either the received file or an error message.
This sequence is sometimes referred to as the request-response loop. We can use our browsers' developer tools to view the client-server communciation that occurs when we load a page. Later in this session, we'll see a browser-free way, too.
Web resources are reachable via URLs. Consider the URL for this course's home page:
https://www.cs.uni.edu/~wallingf/teaching/cs1100/
A URL contains all the information necessary for a web client to request the resource.
-
protocol:
https:
the resource is available using the HTTPS (secure HTTP) protocol -
domain:
www.cs.uni.edu
the domain of the server. We could also have substituted the server's IP address,134.161.120.93, but it's usually easier to remember domain names. -
port: [none given]
If not specified, the default port for HTTP is 80 and
443 for HTTPS. We can specify a port by appending the
port number to the domain name with a colon:
https://www.cs.uni.edu:443. -
path:
/~wallingf/teaching/cs1100/
a filesystem-like path to the resource on the server. It may or may not end with a filename and extension:/~wallingf/teaching/cs1100/index.html -
query string: [none given]
This portion of a URL allows the client to send additional parameters to the server as part of the request, in the form of name-value pairs:
?name=value&name-value...
A URL's origin is the combination of the protocol, the domain, and the port. The origin plays a central role in the web's security model.
URLs can only contain a limited set of characters, and anything outside that set has to be encoded. The set of characters that must be encoded includes spaces, tildes, and non-ASCII characters.
Web Browsers
The most common way to interact on the web is a web browser.
(What is the alternative? Consider the command-line program
curl, with options "--include" and "--verbose".)
A web browser implements of the web's open standards. It knows how to communicate using HTTP, DNS, and other protocols over the network in order to request resources via URLs. It also contains parsers for the web's programming languages and knows how to render, execute, and lay out web content for the user. Browsers also contain lots of security features, which enables users to download and run untrusted code — code from a random server on the web — without fear of infecting their computers.
Your web browser is a complex piece of software!
As a web developer, you can never know for sure which browser your users will have. This means you have to test your web applications in different browsers and on different platforms in order to make sure the experience is good for as many people as possible.
Static versus Dynamic Websites
Every web page is displayed as a result of a request-response loop. However, what happens on the client and the server depends on the type of the website.
A static web page is an HTML file that resides on the server. When the server receives a request for that file, it locates the file and sends it as-is. All of the pages on the course website are static.
A dynamic web page is different. Even though we still see HTML rendered in the browser, that HTML is generated by a program that runs on the server. This program generates the HTML because the content depends on the request: what was requested, by whom, in what context, and so on. Most commercial websites these days are dynamic. If we examine the source code of such a page, most likely the code we see was generated by a program.
The focus of this course is client-side coding, which refers to static pages. That is, the browser on your computer processes the HTML, CSS, and JavaScript on the page. The JavaScript is used mostly for visual effects and for basic validation of the data that users submit through forms. (These are the topics of Week 13 and 14 of the course.)
In server-side coding, we typically write programs that reside on the server. They process user input, get data from external sources such as a database, and generate HTML code to be sent back to the client.
However, this distinction mapping client-side coding to static websites and server-side coding to dynamic websites has become a relic of the past. Today, client-side code can process user input, get data from external sources such as a database, and generate HTML. We can even use JavaScript to communicate with programs on the server, which respond by sending newly-generated content. We may discuss this idea in more detail in the last week of the course.
For this reason, client-side coding today can be far more complex than it was in the not-so-distant past. In our course, we focus on the static side of web development. If you are interested in doing more, I enourage you to look beyond the topics we cover in class; what you will find is facinating technology!
So, What's the Difference Between the Internet and the Web?
In the words of Tim Berners-Lee:
The Internet ('Net) is a network of networks. Basically it is made from computers and cables. What Vint Cerf and Bob Kahn did was to figure out how this could be used to send around little "packets" of information. As Vint points out, a packet is a bit like a postcard with a simple address on it. If you put the right address on a packet, and gave it to any computer which is connected as part of the Net, each computer would figure out which cable to send it down next so that it would get to its destination. That's what the Internet does. It delivers packets—anywhere in the world, normally well under a second.
Lots of different sort of programs use the Internet: electronic mail, for example, was around long before the global hypertext system I invented and called the World Wide Web ('Web). Now, videoconferencing and streamed audio channels are among other things which, like the Web, encode information in different ways and use different languages between computers ("protocols") to provide a service.
The Web is an abstract (imaginary) space of information. On the Net, you find computers—on the Web, you find documents, sounds, videos,... information. On the Net, the connections are cables between computers; on the Web, connections are hypertext links. The Web exists because of programs which communicate between computers on the Net. The Web could not be without the Net. The Web made the net useful because people are really interested in information (not to mention knowledge and wisdom!) and don't really want to have know about computers and cables.
Further Resources (Optional)
There are many sources on the history of the Internet and the World Wide Web: detailed timelines, collections of curious facts, definitive papers and big ideas that predated today's technology. Here are just a few. If you are interested in learning more, check them out.
- Brief History of the Internet is a paper describing the origins and history of the Internet, written by some of its creators.
- As We May Think is an article by Vannevar Bush, published in The Atlantic in 1945, describing a hypothetical mechanical device called the Memex, which would enable links between documents. The goal was to make "more accessible our bewildering store of knowledge". This paper is considered by many people to be the intellectual founding of the web.
- The Memex, even as a theoretical concept, was a precursor of hypertext, a concept proposed by Ted Nelson in 1965: a digital file structure where "interlinking" between documents provided access to information in a nonlinear manner.
- This is a short timeline of the World Wide Web's origins and early history.
- Much more is available on the Internet Society's web site.